The one platform to identify and reduce cyber risk
Cyrisma brings together the data, tools, and workflows you need to reduce risk, get compliant, and drive business resiliency – all in one place.


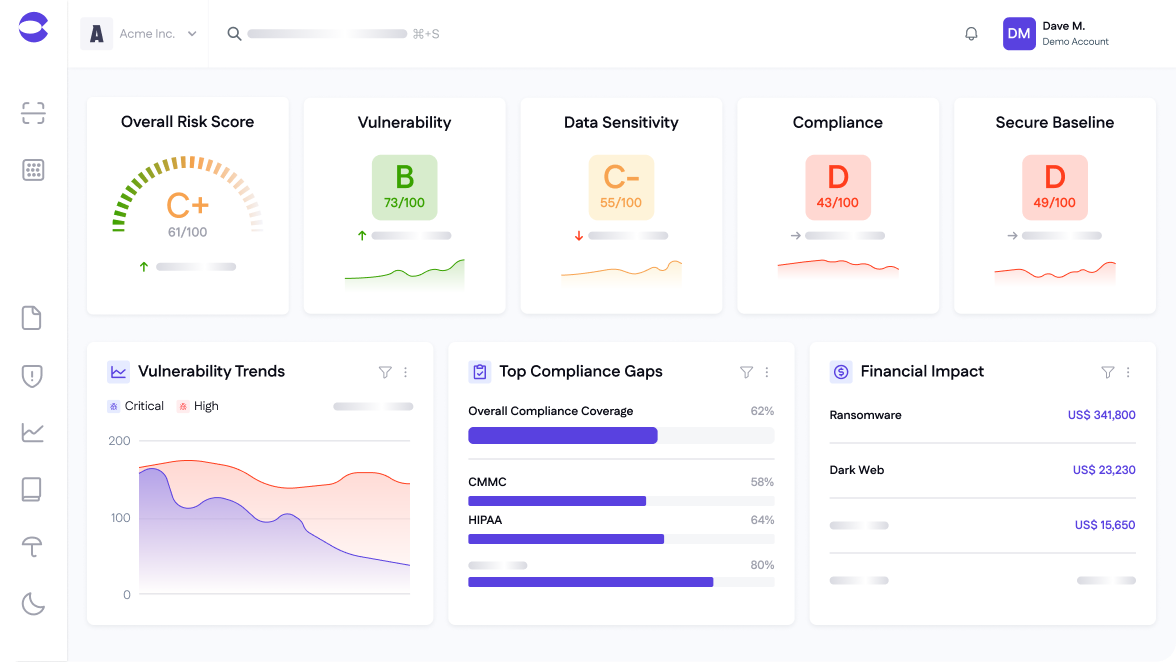





Manage cyber risk from end-to-end
Risk-based Vulnerability Management
Mitigate real threats faster by focusing on what matters most. Use contextual risk scoring to prioritize high-risk vulnerabilities, reduce noise, and enable quicker and more effective remediation.

Data Discovery and Classification
Discover, classify, and protect sensitive data across every environment. Automatically locate, classify, and assess exposure of regulated information - on-prem or in the cloud - to keep clients secure and compliant without complex tools or manual audits.

Attack Surface Management
Gain full visibility into your attack surface to manage and reduce risk.

Compliance Management
Stay audit-ready and demonstrate compliance with less effort. Cyrisma automatically maps risks and findings to major frameworks - helping MSPs generate compliance assessments and reports, demonstrate value, and build recurring compliance services.

Users love us









Trusted by security leaders







Events, updates and resources
View all


Turn Risk and Compliance Into Revenue
Get a DemoFrequently asked questions
Cyrisma is a unified cyber risk and compliance platform for MSPs to identify and reduce cyber risk. It combines vulnerability management, attack surface monitoring, data discovery, secure baseline configuration, and compliance tracking into a single lightweight, easy-to-use solution.
Cyrisma is purpose-built for Managed Service Providers (MSPs) and Managed Security Service Providers (MSSPs) that want to turn risk and compliance into revenue. Using Cyrisma, they can ensure seamless service delivery, simplify operations, scale security offerings, and increase profitability without too many tools or tech fatigue.
Cyrisma’s cloud-based deployment and lightweight agent mean you can onboard new clients in minutes. You can start scanning and generating reports for your clients the same day you sign up.
Unlike other cybersecurity tools, Cyrisma consolidates multiple security functions into one platform built specifically for the channel - multi-tenant, cost-efficient, and easy to deploy across dozens and hundreds of clients.
Yes - Cyrisma can replace multiple standalone tools for vulnerability scanning, asset inventory, data discovery, and compliance tracking. Most partners report a 40% reduction in tooling costs after adopting Cyrisma.


